第1部分 创建多线程
C++11创建新线程
c++11中新增了对线程的支持,我们可以利用std::thread类添加新线程。
编译时需要添加头文件:
1 |
并使用命令:
1 | g++ -std=c++11 sample.cpp -lpthread |
std::thread
在程序中创建线程的命令如下:
1 | std::thread thObj(<CALLBACK>); |
该对象创建后启动一个新线程,这个新线程与主线程并行存在,并立即执行CALLBACK函数。
std::thread对象支持三种回调函数类型:
- 函数指针
- Functor
- Lambda
下面以Functor为例,创建一个新的线程:
1 |
|
区分不同的线程
每一个线程都绑定了一个独特的ID,我们可以调用std::thread::get_id()函数来获得该id,以便区分他们。
1 |
|
第2部分 线程结束的控制
正如申请了内存,结束时必须主动释放一样,线程的管理也需要有始有终。当线程启动后,我们必须在std::thread实例销毁之前,显式说明我们如何处理实例对应的线程的结束状态。我们可以选择接合(join)或者分离(detach)子线程。如果在std::thread实例销毁之前,程序员没有显式指定如何处理线程的结束状态,那么在实例的析构函数中,会调用std::terminate()函数,终止整个程序。
使用std::thread::join()接合线程
主线程可以选择接合子线程,再子线程退出之前,主线程保持挂起。
下面给出一个例子,假如主线程需要启动10个工作线程,并要求在创建这些线程后,主函数必须等待他们执行完后,才会继续执行。
1 |
|
使用std::thread::detach()分离线程
如果选择分离子线程,主线程丧失了对子线程的控制权,转而由C++运行库接管。这时有两个需要注意的地方:
- 主线程结束后,子线程可能仍在运行,因而可以作为守护线程。
- 主线程结束伴随着资源的销毁,需要保证子线程没有引用这些资源。
谨慎使用detach()和join()
情形1 杜绝调用线程实例已经不存在的std::thread对象
当一个std::thread对象的join()函数被调用并返回后,与这个std::thread对象对应的线程实例已经不存在。如果继续调用join()函数,会导致程序终止。
1 | std::thread threadObj( (WorkerThread()) ); |
与上述情况类似,detach()函数使得std::thread对象不再和任何实例存在联系。这时如果第二次调用这个std::thread对象的detach()函数,会导致程序终止。
1 | std::thread threadObj( (WorkerThread()) ); |
因此,每次调用join()和detach(),我们需要检查是否可以调用,通常依据std::thread::joinable()函数的返回值判断。
1 | std::thread threadObj( (WorkerThread()) ); |
情形2 不要忘记调用std::thread对象的join或detach方法
如果创建一个新的std::thread对象后,其join()或detach()都没有调用,那么当该对象析构时,整个程序将会终止。因为在线程对象的析构函数中会检查对应线程是否依然joinable,如果是,则调用std::terminate()终止整个程序。
另外,我们无法保证运行在子线程中的代码不会发生异常。如果子线程抛出的异常没有被调用者处理,那么这个异常会导致整个程序终止。又如果子线程抛出的异常,调用者在处理时没有决定线程的接合或分离,呢么std::thread的销毁可能会绕过正常的接合或分离逻辑,调用std::terminate()终止整个进程。
对于可能发生资源泄漏的情况,我们可以考虑用RAII的思想,将线程资源封装到ThreadGuard中处理这种异常安全问题。
1 | struct ThreadGuard { |
这是一个典型的利用 RAII 保护资源的例子。不论 wk_thread 对应的线程如何退出 (3),守卫变量 g 都会在声明周期结束是,帮助 wk_thread 确认结束状态 (1)(2)。
第3部分 向线程中传参
向std::thread传递简单参数
只需要在std::thread的构造函数中添加额外的参数即可,如下:
1 |
|
向std::thread传递引用
在创建thread对象时,默认情况下参数是被拷贝到线程空间的堆栈中,即使传递的参数是引用类型,线程函数中的引用参数是引用复制在新线程的堆栈中的临时值。因此,使用常用的引用传参并不能让线程修改外界参数。解决方法是使用std::ref(),如:
1 |
|
向std::thread传递成员函数作为线程函数
将成员函数的指针作为CALLBACK函数参数,将对象指针作为第二个参数,传递给std::thread,示例如下:
1 |
|
第4部分 数据共享和竞争态
多线程环境中,线程间的数据共享很容易,但是可能产生竞争态。竞争态是指当两个或多个线程同时访问同一个内存空间的数据,且这些线程中有一个或多个线程修改了该数据,这会导致难以预测的结果。
竞争态难以被发现,因为不是任何时候都会发生。只有当多个线程的执行顺序造成难以预测的结果时,竞争态才会发生。
竞争态的实际例子
下面的例子展示了一个钱包(Wallet)类,这个类提供了一些服务,比如addMoney()。这个成员函数通过一个特定的账户,向钱包里加入钱。
1 | class Wallet{ |
现在创建5个线程,这些线程共享一个Wallet类,并同时调用addMoney()向其中添加1000元钱。我们期望最后钱包中有5000元钱。但是,由于所有线程同时修改同一个数据,可能存在一些场景中,钱包中的钱小于5000。
1 | int testMultithreadedWallet(){ |
什么原因导致这种情况?
在addMoney()函数中,每个线程都会同时修改mMoney成员变量。这个过程可以分解成三个机器指令:
- 将mMoney的值加载到寄存器中
- 增加寄存器中的值
- 使用寄存器中的值更新mMoney的值
在下面的情况中,两个增加操作之一会被忽略。

4. 如何避免竞争态?
可以通过线程锁机制,每个线程需要在访问数据前,锁定该数据,访问结束再解锁。
第5部分 使用互斥锁
第4部分,我们解释了竞争态的概念,本节我们将如何使用互斥锁避免竞争态。
std::mutex
在c++11 线程库中,互斥锁std::mutex包含在<mutex>头文件中。这个类别包含两个方法,lock()和unlock。
以上节中的钱包为例,我们在addMoney函数中使用两个函数,保证数据安全。
1 |
|
现在再测试,发现不会出现钱包内少于5000的情况。因为互斥锁保证了每一个线程在结束修改钱包时,另一个线程才会开始修改钱包。
Mutex引入的新问题
当时如果我们忘记在函数末尾解锁,或者出现异常线程退出的时候,就会出现一个线程退出,另一个线程陷入永远等待的情况。这种情况尽管可以通过缜密的条件代码实现,但是非常繁琐。为了简化操作,可以采用std::lock_guard或者std::unique_lock避免。(这里采用了一种叫做RAII的设计思想,可以参考另一篇博客)。
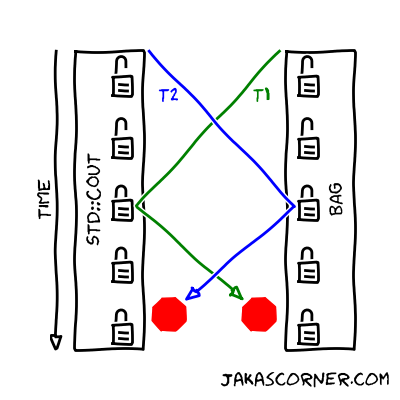
另外,多个互斥锁可能导致线程间互相等待对方解锁从而陷入永远等待的情况,被称为线程死锁,如下图所示。
std::lock_guard
std::lock_guard为互斥锁提供了RAII。他封装了互斥锁,并在构造函数中锁定了这个互斥锁;当它析构时,将释放互斥锁。
1 | class Wallet |
std::unique_lock
std::unique_lock()也可以实现std::lock_guard()的效果。区别在于,std::unique_lock为程序员提供了lock()和unlock()函数,使得可以自由控制互斥锁的状态。一般在一下两种情况下,我们必须使用std::unique_lock()
1. 信号量函数需要std::unique_lock作为输入
信号量函数std::condition_variable::wait()解锁信号量,并等待std::condition_variable::notify_one()函数调用。然后,wait()函数重新上锁,接着执行程序。
由于wait()函数需要对互斥锁进行上锁和解锁操作,因此必须使用std::unique_lock。
2. 实现更好的并行
假设有一个函数,前半部分需要使用共享资源,后半部分仅仅处理局部资源。显然,我们需要在函数第一部分对共享变量上锁。我们可以选择std::lock_guard对变量上锁,并在函数结束时自动解锁。但是函数在执行完第一部分后就解锁是一个更好的选择,因为这样其他线程可以更快的使用这个共享变量。这时就需要使用std::unique_lock对变量上锁,并在函数第一部分执行完后使用unlock()解锁变量。